Ingest Jobs
When new logs are offloaded, or artifacts added to the system,
the scheduler will start kicking off “ingest” batch jobs against those
artifacts. You can configure any number of batch jobs to run when a new log
is added.
These jobs are responsible for doing things like extracting metadata, creation of videos, outputting pose, validating data, or can even be used for non-catalog related purposes, such as running your own checks or ETL jobs.
You can check on your ingest job’s progress by browsing ot your log:
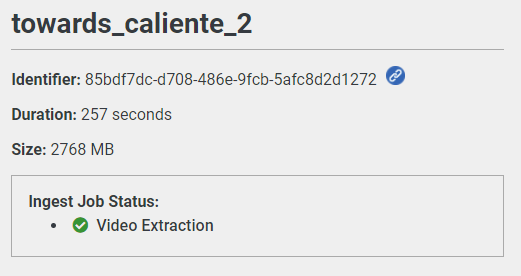
Clicking on any of those jobs will give you its recorded standard output, to help you debug errors (in the event that there are any):
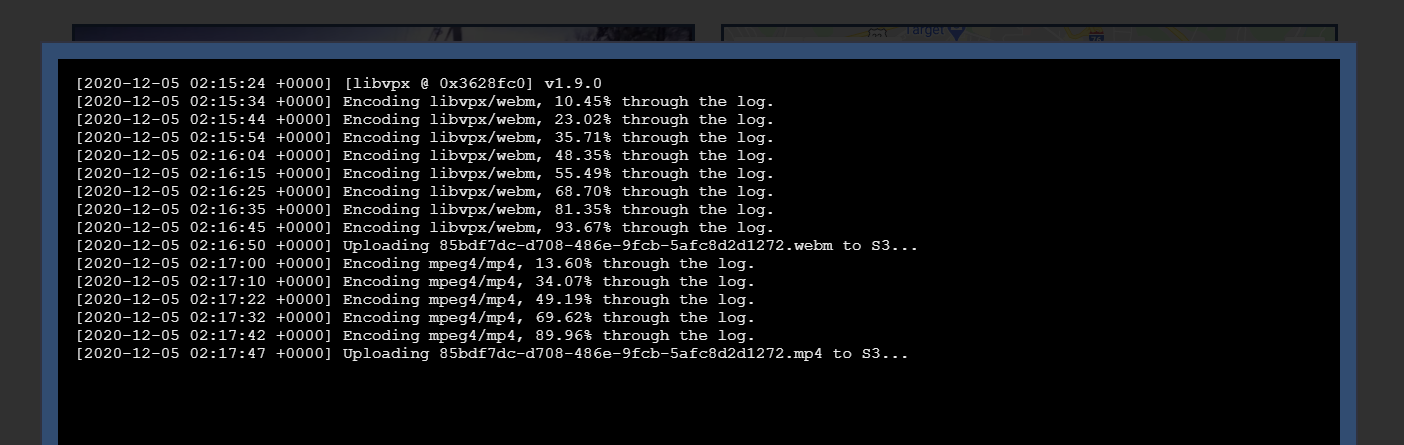
While the job is running, this output will automatically update every few seconds.
Job Rules
Each job has rules that determine what artifacts it will run against. The first such rule is simply the organization the job was created under.
A job will only run against artifacts that are within the same organization
as the job. The exception to this is are ‘global’ ingest jobs, defined by
an organization GUID of 77777777-7777-4777-7777-777777777777. These require
administrator access to create, and will run against all logs ingested.
You can also have finer grained rules. These come in the form of a series
of individual rules such as <LHS> <COMPARATOR> <RHS>, where the left hand
side and right hand side are expressions, and the compator can be ’equals’
or ‘does not equal’.
A typical rule might be "${ARTIFACT_TYPE}" "Equals" "Log", which would
mean that the ingest rule only runs on logs.
Rules can be defined to look at artifact types, identifiers, or attributes.
For example, if your artifact/log has an attribute called ROBOT, you can
create a rule "${ROBOT}" "Equals" "TestRobot". This would only run on artifacts
related to TestRobot.
You can have multiple rules specified. They are all “anded” together (in other words, they must all be true).
Adding New Jobs (GUI)
You can add custom jobs to execute each time a new artifact is ingested. By default, adding a new job will not execute against older artifacts. You must manually request that those artifacts are reingested. that job run against it (“backfilled”).
You can use jobs to process artifacts as they come in, extracting useful data for other downstream tools to make use of.
To add a new job through the web interface, move to the ‘Settings’ page in the top-right corner and click on “Ingest Jobs”, then click on “Add New Job”.
You should see a screen that looks like this:
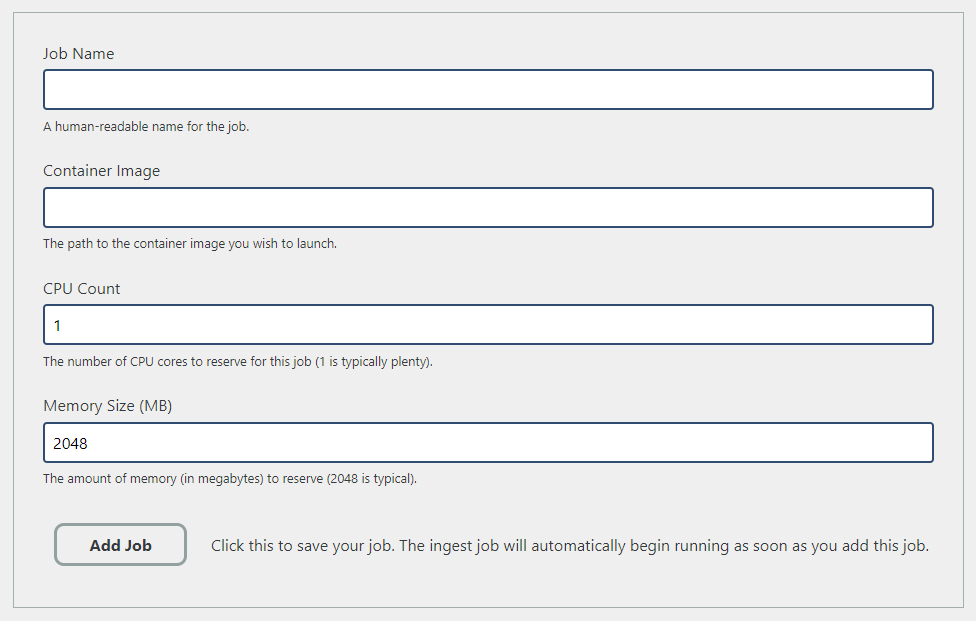
Fill in the details as appropriate, then click ‘Add Job’.
Adding New Jobs (CLI)
You can use the ark-catalog-ingest-tool to add new ingest
jobs to the system. This is done by creating a template of
your ingest job, such as:
config:
default:
name: "Example Job"
organization_id: "<organization GUID>"
container_image: "<container url>"
cpu_count: 2
memory_size_mb: 4096
timeout_s: 3600
command:
- "${ARTIFACT_ID}"
rules:
rules:
- left_type: "${ARTIFACT_TYPE}"
comparator: "Equals"
right_type: "Log"
You can see here that this job will be called ‘Example Job’, will have 2 cores and 4GB of RAM, and execute against any log artifact.
To actually create this job, use the ark-catalog-ingest-tool:
~/ark$ ./build/ark-catalog-ingest-tool --create-ingest-job "path/to/yaml"
This will return success or failure based on if your job is valid and you have permission to add such a job.
Listing Jobs
You can view high level details about ingest jobs from the Catalog frontend. If
you want to see additional details, use the ark-catalog-ingest-tool:
~/ark$ ./build/ark-catalog-ingest-tool --list-ingest-jobs
Extract Camera Video
Identifier: 2
Organization: 77777777-7777-4777-7777-777777777777
Container Image: 095412845506.dkr.ecr.us-east-1.amazonaws.com/2ea25035-6aa4-42fb-9955-92288ea1b972/catalog/extract-video
Core Count: 2
Memory Size: 2048MB
Timeout: 3600s
Command: ${ARTIFACT_ID}
Rules:
'${ARTIFACT_TYPE}' Equals 'Log'
From here, you can see that there is a single ingest job called ’extract camera video’. It
has an organizational GUID of 77777777-7777-4777-7777-777777777777 which means it applies
to all logs across all organizations.
Updating Jobs
You can update existing jobs similarly to creating jobs. Again, use the ark-catalog-ingest-tool,
and pass it the path to an ingest job YAML file.
One key difference from creating inject jobs is you must pass in the job definition identifier that you wish to update. For example:
~ark$ /build/ark-catalog-ingest-tool --update-ingest-job "path/to/yaml" --ingest-job-definition-id "job-id"
This will return success or failure based on if the job is updated. All of the sames rules apply for updating a job as creating a job.
Deleting Jobs
You can completely delete a job with the ark-catalog-ingest-tool. You can only delete jobs that
were created in your organization (and you must be an admin to delete global jobs).
When a job is deleted, not only will it no longer affect any new artifacts, but it will also remove all previously-run job state from artifacts it had already run against. Any attachments will remain; simply the standard output of the job run (and job state) will be removed.
To delete a job, you must supply the job definition identifier:
./build/ark-catalog-ingest-tool --delete-ingest-job "job-id"
Execution
The ‘container image’ references a Docker registry or ECR that contains the container you wish to execute. It is assumed that the container has an ENTRYPOINT defined with the binary that you wish to launch.
You provide the command line that should be given to the container’s
entry point. A typical example is ${ARTIFACT_ID} which will resolve
to the GUID of the artifact that is being ingested.
The machines that run the container image are hosted on m5a.xlarge
instances on AWS.
Reingesting Artifacts
You can reingest a particular artifact with the ark-catalog-ingest-tool as such:
~/ark$ ./build/ark-catalog-ingest-tool --reingest-artifact <GUID>
As-is, that command will re-run all matching ingest jobs on the given artifact (in other words, any ingest job whose rules match the artifact will be re-run).
You an also use the --filter-job-definition command line argument to only rerun one
particular ingest job on an artifact.
Finally, if you are an administrator, you can use the --reingest-all-artifacts flag to
reingest all of the artifacts in the catalog. It’s recommended that you further filter this
with --filter-job-definition or --filter-artifact-type to avoid creation of a large
number of jobs.